-

2025年7月
有機化学の限界を超える!「世界初」を何度も生み出す思考技術
~「誰も触れない」領域にこそ大発見が眠っている~(後編)後編では、井本先生に「ヒ素」に関する研究についてお話いただきました。
「ヒ素」と聞くと怖いイメージが先行してしまいますが、井本先生は誰も扱いたがらなかった「有機ヒ素化合物」の研究に取り組み、これまで世界が発見できなかったことをいくつも発見され、元素研究の前進に大きく寄与されています。
なぜ「ヒ素」研究に取り組んだのか。その考えをお話しいただきながら、研究の醍醐味についてお話しいただきました。そこには研究を超えて、私たちが社会の中で豊かに生きていくためのヒントが散りばめられているように思います。
理論では到達できなかった世界一の発見
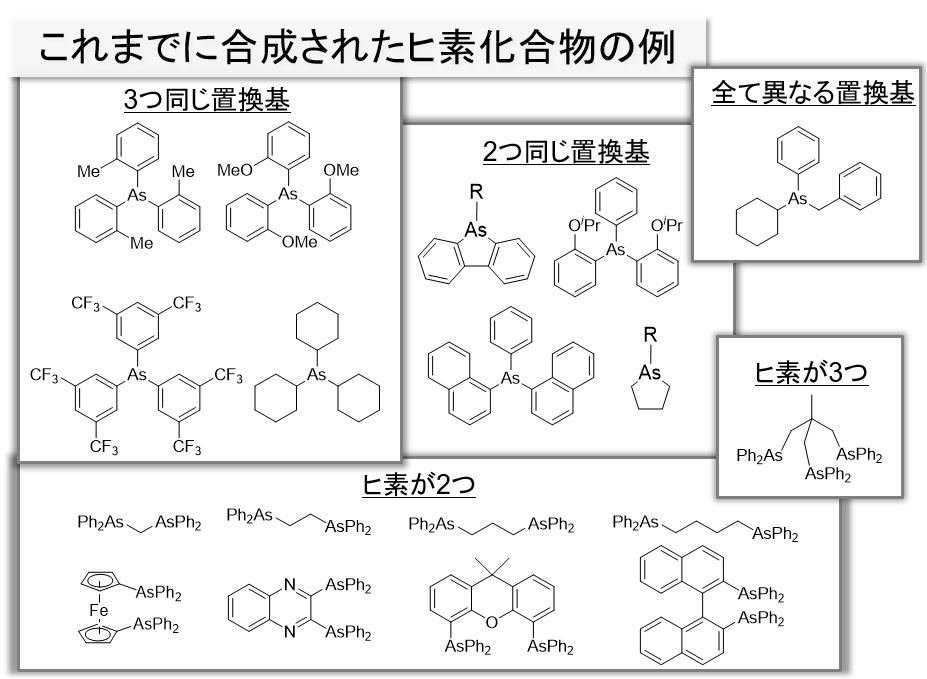
これまで誰も扱いたがらなかった「ヒ素」という元素にも注目しています。
「ヒ素」と聞くと怖いイメージを連想するかもしれません。実際、有機化学の分野でも「ヒ素」は注目されながら、一方で危険だとみなされ、世界的に見ても有機ヒ素化合物の合成実験が盛んに行われることはありませんでした。

有機ヒ素化合物の物性についての研究といえば、もっぱらパソコン上でシミュレーションをするというもので、確かに安全な方法ではありますが、あくまで想像の域を越えません。
重要なのは「実験」すること。「実験」とは、唯一自然界が我々にフィードバックを返してくれる貴重な機会です。そこで得られる発見は、パソコン上で得られるものとは比較できないほど大きなインパクトがあります。
ヒ素は私たちの人体に欠かせない元素ですし、お米や海藻類などの食物にも含まれている身近な元素で、世界中に分布しており、有機化合物に組み入れても安定である等の魅力があります。
さらには、周期表を見てみると、典型元素のど真ん中に位置しています。

「こんなにも目立つところにある物質であるにも関わらず、なぜ誰も扱わないのか」
私の中で、長年気になっていた存在でもありました。
人がまだ手をつけていない領域には、絶対に新しい発見があります。ヒ素を使って新しい物質を作れば、予想を遥かに超えた発見が見つかる可能性が高いです。
ヒ素は「どんなポテンシャルを持っているのか?」 「どうすればそのポテンシャルを発揮させられるのか?」。こう考えてみると好奇心が湧いてきませんか。
ヒ素が忌み嫌われている理由
では、有用性が高いと期待されている物質であるにもかかわらず、なぜそれほどまでに忌み嫌われているのでしょうか。
問題は、有機物にヒ素を組み入れる際に必要となる合成原料にありました。その原料の一部は、化学兵器にもなるほどの毒物が含まれていたのです。
つまり、ヒ素からできる合成物が危ないのではなく、その作り方に危険があったということです。
それがわかった時に、「安全に有機ヒ素化合物を合成する方法を開発すればいいのでは」という発想が生まれ、まずは安全な合成方法を研究するところから始まりました。
ヒ素が危険とされている理由を根本から紐解いて、それを解決できる技術さえ開発すれば、普通にヒ素は使えるということです。
その結果、世界で初めてパソコン上でしか扱えなかったヒ素を、極めて安全な方法で、現実の世界で扱えるようになったのです。
謎めいていた「ヒ素」の正体が見えてきた
最初にやったことは、パソコン上で理論的に予測されていたものを実証してみるという実験でした。
確かに精度の高い予測だけあって、実験結果と概ね合致していました。しかし、予測できることは限られており、未知の部分の方が圧倒的に大きく、実験してみるまでわかりません。
実際に実験を繰り返すなかで、思ってもみなかった新しい性質をいくつも発見することができました。
有機ヒ素化合物は、空気中で極めて安定しており、実用性に優れた材料であることが明らかになったのです。
そのほかに、ヒ素が得意なことや不得意なことも徐々にわかってきました。
有機ヒ素化合物は光ることがそこまで得意ではありません。しかし「エネルギーは一体どこに使われているのだろう」と視点を変えてみると、エネルギーの多くを「物質を変換する」ことに使っていたことがわかりました。その結果、光触媒へ応用できるのではないかという考えのもと、新たな研究がスタートすることになりました。
このように視点を変えてみることで、光らないことさえもその元素の個性となり、有用な性質となるのです。
また、ヒ素を使って生み出した分子が、様々な分野で世界一の値を出すことにも成功しています。

つまり、パソコン上でシミュレーションしているだけでは分からなかった事実が次々と明らかになり、謎めいていたヒ素の性質を理解する、大きな機会となったのです。
結果的に、元素研究の前進に大きく貢献できたのではないかと考えています。
「正解」を探すより「視点」を探す
通常、世界一を目指すのであれば、想像以上に長い年月をかけて懸命に努力を重ねる必要がありますが、私の研究テーマは常に、まだ誰も手をつけていない新しい領域にあるので、世界最高値や世界初の現象が唐突に出てくることも珍しくありません。
元素の周期表を見渡せば、ヒ素以外にもあまり手をつけられていない元素はたくさんあるわけで、それだけ大きな発見や可能性が眠っているということでしょう。
この研究領域に対して「新しいものが作れれば何をしてもいい。どんな結果になってもいい」という極度の自由を設け、好奇心に従って研究を進めることで、新しい発見と日々出会うことができます。
その好奇心がどこに辿り着くのかは、その時点ではわかりません。実験を重ねるだけ、新しいものや発見と出会い、それが土台となって、さらに未知の研究へと足を進めていくことができます。
研究を通じて、豊かな価値観を手に入れる
新しいものに取り組めば、必然的に競争相手はいなくなります。そうすれば、誰かと比較したり競争したりするのではなく、100%純粋な自分の興味・関心に従って没頭できる有意義な時間となります。
だからこそ、この研究室にくる学生には、自分の個性や興味・関心を軸にした研究に励んで欲しいと考えています。

(学生と一緒に研究に取り組む様子)
研究する時間の中で、正解・不正解という狭い評価軸に縛られない物事の捉え方や自由な発想力を培って欲しいですし、その価値観が、きっと今後の人生や社会を生きていく上で大いに役立つでしょう。
私たちは、ついつい物事を二元論で見てしまう傾向があるように思います。
人生においては、成功と失敗、勝ちと負け。学業であれば、正解と不正解、有機と無機などです。
しかしこのような区別を設けることは、あらゆる可能性を見落とすことにつながります。
前編でもお伝えしたように、有機材料と無機材料の垣根を取り払うことで、全く新しい物質が生まれる可能性が爆発的に広がります。それが世界を変えてしまうこともあるでしょう。
同じように、人生においても「失敗だ」と反射的に決めつけず、そこに隠れている発見や面白さに気づくことができれば、それが転機になる可能性だってあります。
決めつけさえしなければ、期待していた以上のものを発見できたり、得られることの方が多いのではないでしょうか。
このように、化学は人生を生きていくうえでの大切な考え方やものごとの捉え方を教えてくれる学問であると考えています。
研究者プロフィール

主な発表論文・関連特許
Combination of Arsines and Tris(pentafluorophenyl)borane towards Frustrated Lewis Pair
著者名:Tomoharu Onishi, Akifumi Sumida, Chihiro Okochi, Yusuke Miyake, Kenji Kanaori, Takahiro Iwamoto, Kensuke Naka, Hiroaki Imoto
掲載誌名:Chemistry – A European Journal
出版年月:2025年04月Polymethylene with Cage Silsesquioxane: Densely Grafted Structure Prevents Side-Chain Crystallization
著者名:Yu Tomioka, Tomoki Yasui, Kensuke Naka, Hiroaki Imoto
掲載誌名:Polymer Chemistry
出版年月:2025年1月Dithienoarsinines: stable and planar π-extended arsabenzenes
著者名:Akifumi Sumida, Akinori Saeki, Kyohei Matsuo, Kensuke Naka, Hiroaki Imoto
掲載誌名:Chemical Science 16(3) 1126-1135
出版年月:2025年An ionic liquid containing arsonium cation
著者名:Ryoto Inaba, Tomohiro Imai, Showa Kitajima, Hitoshi Kasai, Kouki Oka, Ryoyu Hifumi, Ikuyoshi Tomita, Masahiro Yoshizawa-Fujita, Kensuke Naka, Hiroaki Imoto
掲載誌名:Chemical Communications 60(95) 14022-14025
出版年月:2024年10月Open and Closed Cage Silsesquioxane Dimers
著者名:Honoka Yonezawa, Kensuke Naka, Hiroaki Imoto
掲載誌名:ChemPlusChem 89(11)
出版年月:2024年8月- 産学連携や研究支援に興味がある方(産学公連携推進センターHP)
- 紹介教員に応援メッセージを送りたい方(メッセージフォーム)
- 大学や学生を支援したい方(基金事業)
- 受験を考えている方(入試情報)
- 大学全体について知りたい方(京都工芸繊維大学HP)